Taalcanon
alles wat je altijd al had willen weten over taal
‘Hé Siri, wat voor weer wordt het morgen?’ ‘Hé Google, zet het koffiezetapparaat aan.’ In heel wat Nederlandse huishoudens staat tegenwoordig een virtuele assistent, die je via spraakbesturing vragen kunt stellen. Ook praat je steeds vaker tegen een computer als je belt met een klantenservice. Automatische spraakherkenning is de laatste jaren dan ook snel veel beter geworden.
Eigenlijk is het best bijzonder hoe makkelijk mensen elkaar doorgaans verstaan. Zelfs al praat iemand met een volle mond, in een drukke kroeg of met een Frans accent, in de stroom van klanken kun je de woorden meestal prima herkennen. Tot 2012 probeerden taaltechnologen computers spraak te laten herkennen op ongeveer dezelfde manier als onze hersenen dat doen. De resultaten waren best aardig, maar de methode was nog niet breed inzetbaar. Met de komst van technieken uit de kunstmatige intelligentie is daar verandering in gekomen.
Woorden voorspellen
Laten we eerst eens kijken naar hoe mensen spraak ontcijferen. Je hoort geen spaties tussen woorden, dus een zin als Ik heb het formulier van de verzekeringsmaatschappij ingevuld klinkt in gesproken taal ongeveer als: keputformelierfandefesekringsmaatschepijingevult. Zoals je ziet worden lang niet alle klanken volledig uitgesproken. Je hersenen moeten dus in deze brei van klanken woordgrenzen herkennen en de onvolledige woorden herleiden tot hun officiële vorm.
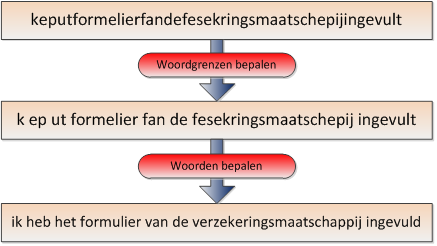
Bij deze spraakherkenning maakt ons brein gebruik van zijn taalmodel met daarin woordkennis en kennis van zinsbouw. Dit taalmodel helpt te voorspellen welke woorden de spreker zegt. Daarbij helpt ook onze kennis van de wereld en wat je zelf al weet van het gespreksonderwerp. Een woord als verzekeringsmaatschappij heb je daardoor vaak al herkend vóórdat de ander het helemaal heeft uitgesproken. En vaak kun je dan ook al voorspellen welk woord erna komt. Hoe beter we een taal kennen en hoe meer we weten over het onderwerp waarover gesproken wordt, des te beter kunnen we dus voorspellen welke woorden er zullen komen en dus hoe beter onze eigen spraakherkenning werkt.
Stap voor stap herkennen
De eerste automatische spraakherkenners werkten op een vergelijkbare manier. Daarbij bepaalt de computer eerst van elke 10 milliseconden in het digitale geluidssignaal welke klank er waarschijnlijk wordt uitgesproken. Hij berekent daarvoor steeds het spectrum, waarin van elke toonhoogte (frequentie) de geluidssterkte (amplitude) wordt aangegeven. Dat spectrum vergelijkt hij met de opgeslagen gegevens van de verschillende spraakklanken om te kijken welke het meest overlapt.
| invoer spraakopname | → | akoestische analyse | → | vergelijken met uitspraakmodel | → | vergelijken met taalmodel | → | uitvoer tekst |
Vervolgens berekent de computer voor de reeks opeenvolgende klanken welke woorden het zouden kunnen zijn. Geen eenvoudige klus, want woorden worden maar zelden heel netjes uitgesproken en vaak is het spraaksignaal vervuild met achtergrondgeluiden. Als de computer is getraind met de spraak van één persoon en diegene spreekt over een vooraf bepaald onderwerp in een heldere opname, zijn de resultaten van deze spraakherkenning vrij aardig. Maar in de praktijk is er meestal geen ruimte voor zo’n specifieke training en zulk beperkt gebruik. We willen dan een systeem met meer flexibiliteit.
Alles-in-één
Deze flexibiliteit is de afgelopen jaren gevonden in een nieuwe methode voor automatische spraakherkenning, die werkt met deep learning-technieken. Dit is een vorm van kunstmatige intelligentie waarbij de computer zelf in grote hoeveelheden trainingsdata op zoek gaat naar patronen. Die patronen worden verwerkt in een neuraal netwerk, dat qua structuur vergelijkbaar is met hoe informatie in onze hersenen wordt opgeslagen. Zo’n netwerk bestaat uit verschillende lagen van neuronen die onderling verbonden zijn en informatie uitwisselen.
| invoer spraakopname | → | neuraal netwerk | → | uitvoer tekst |
Het neurale netwerk voert in zijn eentje alle stappen uit die in de oude methode nog afzonderlijk werden gezet: hij rekent uit welke klanken, woorden en zinnen het meest waarschijnlijk passen bij een stukje geluidsopname. Ook bij deze methode bepalen de trainingsdata in grote mate hoe goed het systeem spraak kan herkennen. Een neuraal netwerk dat is getraind met maar één spreker, zal slecht presteren als hij veel verschillende mensen moet ontcijferen. En een neuraal netwerk dat is getraind met heel veel opnames van een klantenservice, zal een klagende beller beter herkennen dan een kletsende buurvrouw. Maar de deep learning-technieken leveren het neurale netwerk meer dan 100 miljoen parameters op, en daarmee ‘weet’ het veel meer dan met de traditionele modellen.
Door het gebruik van deze deep learning-technieken in combinatie met de beschikbaarheid van grote hoeveelheden data en de toegenomen rekenkracht van computers, zijn de prestaties van automatische spraakherkenners de afgelopen jaren flink verbeterd. Niet alleen voor het Engels, waar de ontwikkelaars in eerste instantie vooral op gericht waren, maar ook voor andere talen, zoals het Nederlands.
Onder optimale omstandigheden herkennen deze systemen spraak voor ongeveer 95 procent correct. Daarbij is het neurale netwerk dan getraind met spraak van (onder andere) dezelfde spreker, die dezelfde woorden gebruikt in min of meer dezelfde opnameomstandigheden. Praat je met een volle mond, in een lawaaiig café of met een buitenlands accent, dan ligt de foutmarge een stuk hoger. Taaltechnologen blijven werken aan deep learning-technieken en neurale netwerken die ook zulke spraak net zo goed kunnen verstaan als wij dat kunnen.
Lees meer
Lees verder op Kennislink:
Reacties
4 reacties op ‘Hoe verstaat de computer wat ik zeg?’
clemens op 7 april 2013 om 14:04
Wanneer komen die computers waar we tegen praten? Ik heb wel eens gehoord dat in Japan deze computers er al zijn. Bedankt voor je antwoorden. Vriendelijke groeten, Clemens
redactie taalcanon op 23 april 2013 om 13:08
Beste Clemens,
Ik kreeg deze week jouw vraag doorgespeeld: Wanneer komen die computers waar we tegen praten. Ik heb wel eens gehoord dat in Japan deze computers er al zijn.
Ik weet niet precies wat je met deze vraag bedoelt want computers waar je tegen kunt praten (en die daar iets zinvols meedoen) bestaan al jaren. Zo bestaat het programma Dragon Dictate (ondertussen bij versie 12) al erg lang en wordt dat veel gebruikt in omstandigheden waar mensen kunnen dicteren en waar dat ook zinvol is. Verder zijn er natuurlijk allerlei telefoniediensten waarbij een deel van de vraag-antwoorden door de computer gedaan wordt, is er Google Voice en Apple’s SIRI en tenslotte zijn er steeds meer apparaatjes (de “duurdere” TomTom’s) en zelfs (goedkopere) auto’s zoals de Ford Focus.
Behalve het dicteerprogramma zijn het allemaal interactieve dialoog-programma’s waarbij gebruikers, zolang ze binnen de context blijven, vrij eenvoudig spraakherkenning kunnen toepassen.
Daarnaast is er nog een enorme wereld waarbij gesproken documenten mbv spraakherkenning doorzoekbaar gemaakt worden. Het wordt de laatste jaren vooral gebruikt voor de ontsluiting van het cultureel erfgoed (Oral History).
Kortom: er is enorm veel, er komt in hoog tempo nog veel meer bij dus of dit was toch betrekkelijk nieuw voor je of je bedoelt eigenlijk iets anders.
Ben benieuwd naar je reactie!
Misschien vind je het leuk om er iets meer over te lezen. Ik heb op mijn homepage een pdf staan met daarin een groot aantal voorbeelden van toepassingen waarbij spraakherkenning gebruikt wordt. Kijk maar of het iets is.
http://wwwhome.cs.utwente.nl/~hessenaj/pub/Spraakherkenning_uit_Twente-2013.pdf
Met vriendelijke groet,
Arjan van Hessen
Danny de Koning op 28 januari 2016 om 11:07
Goedemiddag,
ik vroeg mij af wanneer dit artikel geschreven is. We kunnen nu namelijk wel degelijk tegen computers praten. Denk maar aan Apple’s Siri. We kunnen misschien niet hele menselijke gesprekken voeren maar we kunnen wel degelijk praten met de computer.
Ook hou ik erg van kaas.
Groeten Danny de Koning
redactie taalcanon op 2 februari 2016 om 09:40
Zie de reactie van de auteur hierboven!
Vriendelijke groet, de redactie.